Introduction
Modern smartphones, smart speakers, televisions, and household appliances are increasingly “hearing” us and executing voice commands. The speech recognition technologies behind virtual assistants like Siri, Alexa, or “Alice” rely on massive speech datasets – collections of audio recordings with transcriptions. In this article, we will explore how voice data is collected, prepared, and used for training machine learning models.
A key role in this ecosystem is played by platforms like Speech-data, which specialize in large-scale audio data collection and annotation, ensuring that speech datasets are diverse, accurately labeled, and suitable for training robust machine learning models.
The Importance of High-Quality Datasets
The effectiveness of a speech recognition system directly depends on the quality and volume of training data. As scientists point out, “deep models… are highly data-dependent, and their accuracy varies depending on the dataset.” This means that the more diverse and precise the recordings (including various speakers, accents, and recording conditions), the better the model performs in real-world devices. Speech-data focuses precisely on this task – collecting thousands of hours of voice files and detailed transcriptions to enable developers to create reliable voice interfaces.
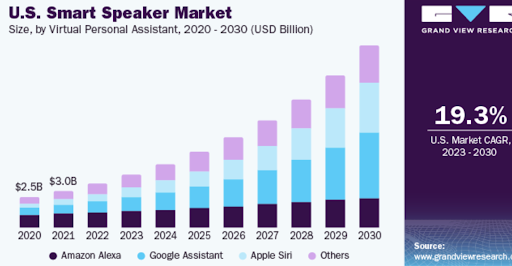
It is also important to highlight the growing scale of the voice device market. By 2030, the global smart speaker market is projected to grow from $7.2 billion (in 2023) to nearly $50 billion (by 2030). This trend underscores that more and more consumers are interacting with technology by voice, and the demand for recognition quality is only increasing. Market growth is driven by “the increased integration of voice assistants and data exchange” and new applications (such as voice shopping).
Building a Speech Dataset: From Raw Audio to Model-Ready Corpus
Despite the popularity of voice technologies, the path from raw audio recording to a trained model is far from simple. The task of dataset development includes collecting diverse speech samples (various speakers, languages, and background noises) and precise annotation. Crowdsourcing, specialized applications, and scripts are often used for voice recording. For example, to obtain a representative dataset, companies may engage hundreds of volunteers worldwide and combine public recordings.
Successful examples of such datasets include English-language LibriSpeech (over 1,000 hours of audio) and Mozilla Common Voice (approximately 33,000 hours across 133 languages).
In the next step, recordings are synchronized with transcriptions (usually manually or semi-automatically), and metadata (gender, age, recording conditions, etc.) is added. This process is carefully automated and verified, as any error in annotation can reduce the accuracy of future recognition. The result is a rich corpus – a “data vault” – which is then used to train AI.
| Dataset | Language(s) | Data Volume (hours) | Application |
| LibriSpeech | English | ~1,000 | Training ASR models |
| Common Voice | Multilingual | ~33,000 | Speech recognition |
| Switchboard | English (telephone) | ~300 | Conversational ASR systems |
| Fisher | English (telephone) | ~2,000 | Telephone ASR |
| AISHELL-2 | Chinese (Mandarin) | ~170 | ASR (Mandarin) |
Composition and Tasks of a Speech Dataset
A typical speech dataset consists of three key components:
- Audio Recordings – digital files containing speech, varying in length and quality (e.g., a quiet classroom or a noisy market).
- Transcriptions – textual representations of the spoken words (either verbatim or with annotations for pauses, stresses, etc.).
- Metadata – information about recording conditions and speakers: gender, age, accent, presence of background noise.
The availability of such data allows for the preparation of models capable of operating in real-world scenarios. For instance, for recognizing commands in a “smart home,” AI must learn to “hear” voices from different rooms and understand people of various ages. Companies, including Speech-data, categorize recordings by context and requirements: simple phrases for smart speakers, conversational dialogues for customer service, multilingual instructions, and so on.
Model training proceeds along two main paths:
- Automatic Speech Recognition (ASR): The model receives an audio recording and its corresponding text, learning to map sound to words. This task is typically handled by deep neural networks with transformer or convolutional-recurrent architectures. Virtual assistants, video subtitles, and dictation applications all utilize ASR.
- Text-to-Speech (TTS): Operating in the opposite direction, the model learns to generate natural speech from a given text. This is necessary for smart speakers to respond to users with a “living” voice.
Furthermore, speech datasets are crucial for speaker identification (recognizing who is speaking) and language recognition. Voice verification is used in security systems, while multilingual datasets allow devices to switch seamlessly between languages like Russian, English, and others.
Classification of Speech Datasets by Purpose
Beyond specific well-known corpora, speech datasets can be broadly classified by their intended application. Each type of dataset serves a distinct purpose in the development of voice technologies, and the choice of dataset directly influences the capabilities of the final model.
| Dataset Type | Primary Purpose | Key Characteristics | Example Use Cases |
| Command & Control | Recognizing short, predefined voice commands | High signal-to-noise ratio; limited vocabulary; often recorded in controlled environments | Smart home devices (turn on lights), TV remote control, automotive infotainment |
| Conversational Speech | Understanding natural, spontaneous dialogue | Includes disfluencies (um, ah), overlapping speech, varied sentence structures; often telephone-quality audio | Virtual assistants, customer service call centers, meeting transcription |
| Multilingual / Code-Switching | Handling multiple languages or switching between them within a single utterance | Contains speakers fluent in multiple languages; includes language labels and mixed-language samples | International smart speakers, translation devices, global voice interfaces |
| Far-Field & Noisy Environment | Recognizing speech from a distance with background noise | Recorded with distant microphones; includes various noise types (music, traffic, crowd chatter) and reverberation | Smart speakers in living rooms, in-car voice systems, industrial voice controls |
| Speech Synthesis (TTS) | Generating natural, expressive synthetic speech | High-quality studio recordings; includes phonetic and prosodic annotations; often features professional voice actors | Audiobooks, navigation voice prompts, accessibility tools for the visually impaired |
Applications in Consumer Electronics
Consumer electronics represent the primary market for speech models. Everyday gadgets actively utilize voice technologies:
- Smart speakers and displays (Amazon Echo, Google Nest, Yandex.Station) constantly “listen” for commands and manage the smart home.
- Smartphones and tablets equipped with Siri, Google Assistant, etc., can dictate text, answer questions, and launch apps.
- Televisions and automobiles support voice search and navigation.
- Household appliances (refrigerators, kettles, air conditioners) are increasingly being equipped with voice interfaces for user convenience.
Across all these devices, the speech recognition model must handle background noise and various accents. For example, a car’s environment is noisy due to the engine, while a living room may have music playing. To ensure stable performance, the training dataset is specifically designed to include such “noises.” This is how the model learns to isolate clean speech. Professionals at Speech-data create these realistic conditions by collecting audio from kitchens, cafes, and transportation to ensure the AI doesn’t get “lost” in the noise.
Data Collection and Model Training
Creating a large and diverse dataset is a labor-intensive process. It typically involves several stages:
- Audio Collection: Audio can be sourced from open repositories (radio broadcasts, podcasts) and proprietary devices. A company might, with consent, collect voice queries from users and incorporate them into the dataset. Crowdsourcing is also effective, with people around the world recording specific phrases as tasks.
- Annotation: Audio files are transcribed. This is often done manually because even the best automatic services can make errors in practice. Speech-data engages linguists and crowdsourced workers, verifying transcriptions through multiple contractors to ensure reliability.
- Cleaning and Balancing: This involves removing defective or irrelevant fragments and balancing the dataset for factors like gender representation and different accents. This is crucial to prevent the model from becoming biased toward a single type of speech. For example, if the data contains too much American English, the system may struggle to understand an Australian accent.
Once the dataset is prepared, model training begins. Pre-trained transformers (like wav2vec 2.0 or Whisper) are currently popular. They are first trained on very large “unlabeled” audio collections and then fine-tuned for a specific task. For instance, Facebook trained wav2vec 2.0 on approximately 1,000 hours of real speech (plus 50,000 hours with augmentation), requiring significant GPU power. For most languages, such resources are unavailable, necessitating either cross-lingual transfer learning or supplementing the dataset with “synthetic” speech generated by TTS.
The availability of large, ready-made datasets significantly accelerates development. Popular corpora include LibriSpeech (English audiobooks), Common Voice (volunteer recordings), and Switchboard (telephone conversations). Another massive corpus is the People’s Speech from MLCommons, containing over 30,000 hours of transcribed conversational English licensed for both academic and commercial use. Such datasets make speech research more accessible, helping to “improve the speed and reliability of recognition systems.”
Case Study: Fixing the “Kitchen Problem”
Let’s look at a realistic example. A team building a smart oven found that their voice recognition accuracy was 95% in the lab, but only 72% in real kitchens.
The Diagnosis:
By analyzing the metadata, they realized their dataset was missing two key elements:
- Far-field audio: Their training data used close-talk microphones (inches from the mouth). The oven had a far-field mic on the hood (feet away).
- Ambient noise: They had no samples of running dishwashers or frying sounds.
The Fix:
They launched a targeted data collection campaign using scenario-based speech. They set up a test kitchen, placed the device on the hood, and asked participants to perform cooking tasks while giving voice commands.
- New Dataset: 100 hours of far-field audio in a noisy kitchen.
- Result: Real-world accuracy jumped to 89% in three weeks.

Challenges and the Future
Despite significant progress, several challenges remain. Models often struggle with unfamiliar conditions: street noise, a poor-quality phone microphone, or new slang can degrade recognition performance. Researchers are experimenting with background augmentation and specialized noise-suppression algorithms, but a universal solution has yet to be found.
Another critical issue is fairness and privacy. If a dataset underrepresents certain groups (such as people with accents or the elderly), the model will perform less accurately for them. Therefore, careful attention is paid to balancing demographics during dataset creation. Data collection must also comply with privacy laws: participants provide consent, and personal information is anonymized and removed. Major projects, including those by Speech-data, rigorously address these concerns.
Looking ahead, several key trends emerge:
- Multilingual and Multimodal Systems: In addition to audio, systems are starting to incorporate video (lip-reading) or sensor signals to improve recognition in noisy environments.
- Self-Supervised Learning: New models are being trained on unlabeled data (without transcriptions), leading to quality improvements when large volumes of raw audio are available.
- Generative Approaches: The integration of generative AI (similar to ChatGPT) into voice assistants is already underway, enabling more natural and contextually appropriate responses.
Conclusion
Artificial intelligence in voice technology is on a path of continuous improvement. However, the foundation for all these advancements remains a high-quality dataset. As stated in a review of deep ASR methods, performance is directly dependent on the training data. Behind the scenes of every successful voice function lies meticulous work with data: collection, annotation, and verification.